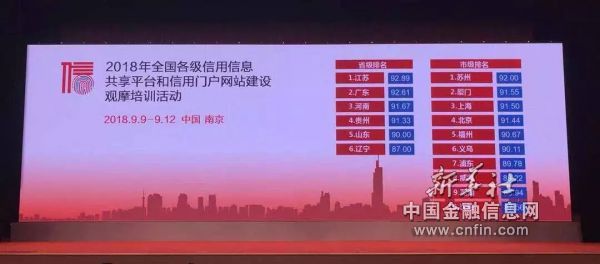
9月12日,2018年全国各级信用信息共享平台和信用网站建设观摩培训正式落下帷幕。经历预算和决赛两个阶段,决出了特色性、标准性和示范性平台和网站,江苏和苏州分获省级组和市级组的第一。

76个省市各具特色,92场汇报场场精彩。各地亮点纷呈,与去年相比,真的是全面超预期。
1、数据量超预期
省级组的数据规模开始进入30亿的量级,城市组的开始进入10亿级。进入决赛的门槛量级也大大提高,一个城市没有2亿条数据几乎说不出口。其次是信用主体实现了全覆盖,法人、自然人,政府机构、社会组织、党员、公务员、重点职业人群,各种主体分类预警加细化,也标志着社会信用体系开始进入精细化管理。比如苏州的政务诚信、智慧监督系统,为从严治党提供保障。
2、应用超预期
去年尚未见到的联合奖惩应用今年已成为各家标配,省级有省级的做法,城市有城市的干法,“双接入、双嵌入”得到了充分体现,“进大厅、进社区”得到了充分展现,信用逐步成为政府行政审批、项目申报、政府采购的必备条件。“事前承诺、事中监管、事后审查”从前到后的全生命周期信用管理模式正在成为现实。“一网通查、一键搞定、一数激发、一图尽览”,广东省对其进行了精彩概括。
“信易+”被认为是社会信用体系的牛鼻子,大概是今年三月份所提的“新生”事物,在各省市也是落地生根。信易贷江苏从省级对接14家银行,苏州中小企业获得首贷资金118亿,信易行苏州与滴滴合作,加大对滴滴司机的信用审查,诚信市民享受优先派车的出行便利,信易游从本地旅游开始,进入跨区合作阶段,全国信用联盟逐步形成。
3、大数据应用超预期
数据是金矿,从观摩会来看,各省市已经开始深挖这做金矿,数据可视化已经是标准动作,展现形式上也是各式各样。有福州的AR模式,还有河南的VR应用,还有江苏的“快递仓”式展现。也许大家都在追求8分钟的展现效果,但背后的努力真的少不了,各种实际的应用也真的不少。比如说信用评价,依赖大数据技术和各种建模理论,开展对个人和企业的信用评价。首当其冲的是桂花分,现场人脸识别,评价个人信用,开创全国先河。接着是茉莉花、白玉兰、玫瑰等各种分,全国的花都要不够用了,所以就有了西楚、白鹭。也正是因为有了这些分,才让信用更有用、更好用,大数据的功劳少不了。还有的就是利用大数据技术识别企业灰名单,精细化企业管理,大数据分析老赖的可偿还能力,让老赖无处遁形。

这些成绩的取得,少不了各地优秀同行的努力,也缺不了各地背后IT服务商的鼎力支持。不管最后成绩如何,76个省市都是全国社会信用体系建设的先进代表,至少代表着各省市地区最先进的水平。然而,从观摩会上的整体表现来看,社会信用体系建设的地区差异愈发明显。
92场演示虽然我没有场场参加,参加的场次还不到其中的一半,但是就参加场次之间的差异还是比较明显的,特别是在城市组,其中的差距我觉得至少是两个等级,有些比赛真的是降维打击。
1、示范之争
这种差异主要体现在各项体系工作的开展上。示范创建城市组织机构、制度保障普遍比较完善,积极思考各种办法迎接各种挑战,更多在考虑应用体系的推进。而有的城市就是一直在跟随,永远在等,希望别人能将一条路踏平了我再走过去,即便向前迈了几步,还停留在收数据等应付考核约谈的层次。所以有人说从决赛情况来看,似乎还是去年示范城市评比的翻版,内容是不一样的内容,味道还是一样的味道。
2、地域之别
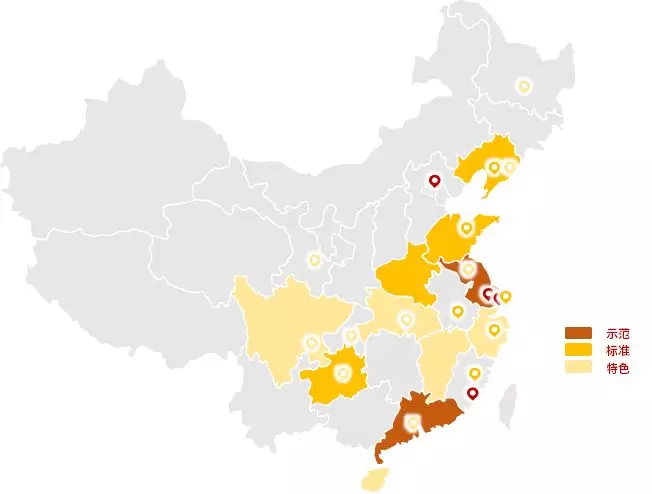
先进地区愈加发达,你追我赶,各种创新应用层出不穷。比如说江苏地区,三个参赛队伍两个第一,一个与决赛仅差0.4分。另外从参加决赛城市分布来看,普遍是东部沿海经济比较发达的城市。有了充分的领导重视、资金保障和应用场景,信用的落地生根也似乎更加顺理成章。
3、企业较量
有的城市真的很努力,但努力却似乎没有好的体现,为什么?信用信息共享平台和信用网站建设观摩比赛,IT服务商是关键。根据去年源点发布的《重磅:招标下的信用中国》数据统计,全国尚未形成有绝对垄断的信用IT服务机构,但是水平之差却逐渐明显。本次参会的76个省市地区,其中的IT服务商至少有50个,全国未参赛的剩余200多个省市地区就更纷杂,但盘踞示范和排名靠前的城市IT服务商却似乎总是这么几家。最后进入决赛的16个参赛省市中十多个基础软件IT服务商,除几个是建设智慧城市的企业外,有几家既能够提供技术,还能够提供业务体系指导并专注信用大数据体系建设和服务的供应商正快速成长。
因此,本次平台和网站的观摩不如说是一场IT服务商之间的观摩比赛的。而我想说的,信用信息共享平台和网站,其实你真的做不来...
本人从2013年开始参与第一轮社会信用体系建设,自2012年国家开启第二轮社会信用体系建设时介入信用信息共享平台和网站建设服务,算是参与比较早的了。亲眼见证了从平台1.0、2.0、3.0的转变,每一次转变都是巨大的里程碑,几乎都需要对自己的知识体系做一次新的重构。时至今日,自我评价只能算是入门。之所以说你做不来,主要是因为信用信息共享平台真的不是一项简单的IT项目,其本质是集数据治理、大数据技术、电子政务、信用管理、信息安全于一体的信息化体系。在信用推进体系过程中你会遇到各式各样的挑战,不知道下一个坑会在哪里?
首先第一个坑就是数据采集。这个坑在当前也许不是最大的,去年信标委的已经出台了信用信息目录的标准规范,为各地信用信息系统建设提供了指导性规范,可对当年的我们来说,那个苦啊,一切都要从头定义,谁让社会信用体系建设的是世界首创,在全球都找不到参考样板。我们要首先去定义哪些是信用信息,还要去考证这些信息是符合哪些理论思想的?现在好了,随着信用信息目录的出台,信用内涵基本介绍清楚,接下来需要的就是我们要对这些目录要梳理,要根据各个部门职责定义,将目录信息分解到“各个部门”去,定标准、下任务,同各个部门进行友好性磋商,确保信用信息能采集到位。“各个部门”也许较为轻巧,但往往应对的是60+以上的部门,需要的是60+部门的知根知底,从容应战啊,还记得流火的七月。
数据采集目录定义完是万里长征的第一步,接下来是真正的数据采集、数据治理,这时你会发现数据治理才是最大的一个“坑”,各个部门所提交的信息质量真的不是你想象的那样。当然,这也怨不了大家,谁让各个部门的信息化状况不一样,业务流程标准不一样呢,这就要求各个部门也提高工作标准,改善工作流程,或者优化信息系统。呵呵呵!作为一个信用中心,或一个第三方IT公司去要求其他部门做这些改变,你可以想象一下难度。我们最能做的就是做各种数据治理,从源头开始,到各种数据的加工过程。我们也计算过,在我们的系统中一条标准数据的产生往往都要经过差不多30个节点的数据处理才能产生。而一个系统中采集的信息项往往是接近1300项的,其中的工作量你可以想象,也说不准哪天信用标准又升级了,采集部门又调整了,两个部门又合并了,这些工作又都是长期的,所以数据治理体系和服务就伴随着软件的不断升级,投入了巨大的精力和金钱。
走完了第二步,开始数据入库,你又不得不思考新的问题,这些数据进来以后我要怎么用,也不能老是堆在这儿,要考虑数据应用。在还没有联合奖惩的时候,我们主动上门,主动为部门去考虑,看看我们能为不能做点什么?去各种推介我们的信用产品、各类信用信息,希望别人能接进来,这是多么高尚的雷锋精神。而后来随着联合奖惩的逐步推进,各种服务也开始主动找上来,对系统也提出了各种更高的要求,要求你的系统能够适应各种网络、开发环境,提供的接口和信息也越来越多,要求你的系统要能主动适配,响应性、稳定性要求越来越高。从此你将淹没在各种对接调试中。
有数据有应用,也许你认为开始万事大吉,这时只能说明你太年经,等到应用真正起来的时候,数据规模才刚刚开始,接下来的数据量增长都将是指数级的增长,今年一千万,明年一个亿不是梦,十个亿也将成为可能。所以你需要做的要开始优化大数据架构,分库分表加索引只是常规操作,有时你不得不应用大数据平台,从此Hadoop、分布式、搜索引擎成为你的常用语,还有人会不断的给你洗脑数据湖、数据云等概念,你会发现自己一下子成为了IT小白。
平台和业务总是那么层层纠缠,相互提升,基础架构提升了,业务应有进一步有了新的需求,大家对信息的需求又有了新的转变,所带来的不是信息缺失,而是如何面对海量的信息冲击,如何快速找到想要的信息?如何挑选出有用的信息这又成为了当前的难题。这些就需要进一步信用数据挖掘,各种算法开始展现,什么分类、聚类,什么逻辑、神经算法,又都开始登上台面,开始精细化和精准化管理之路。对于数据的要求也不再简简单单的客观呈现,要开始考虑对未来的预测,深挖我们看不到的东西。
这些也许你会认为的还是大数据技术,信用还是需要有专业的业务知识。没错,这时真正的信用管理才开始,需要用专业的知识对信用主体的信用管理和信用行为进行评价,这时你要开始了解会计学的知识,还要会信用管理,知道运用粉线管理分析模型,什么是Z积分模型,什么是巴萨利模型,什么是特征分析,什么是评分卡……
这时候,信用管理也许才刚刚开始,前面我们做的也许只不过是IT,有的也许连IT也还没干好呢。
社会信用体系建设永远在路上,我们都才刚刚开始。


















